As we count down to the first block producing epoch, Cardano Canucks has been working hard behind the scenes to ensure that our pool is ready to provide our delegators with the most reliable performance and security.
Included in our site is an architecture page which should answer most high level questions about our architecture, however we have made some recent updates to the architecture to improve two main areas – uptime / reliability and security.
The updates are focused around 2 main areas, availability (up-time) and security. In this blog we will focus on the availability updates.
As for security, we were already following security best practices and had a system to be proud of, however in light of the recent hack into the HAPPY pool where the pool operators node was hacked and pledge stolen, we have further hardened our infrastructure to ensure our pledge is safe, and our delegators rewards are un-interrupted.
Availability Updates
The CANUK pool runs 4 relays and 2 producer nodes in order to maintain maximum uptime. Should up to three of our relays fail, our producer will still be communicating to the network and be able to produce blocks. If our primary producer should fail, we are able to promote the standby leader to be a producing node within minutes of the primary failing.
The existing architecture would ensure high availability should any of the nodes fail, however it did not take into account the possibility of a data center failure – so we’ve updated our architecture to account for that.
For people not familiar with AWS, their infrastructure is divided into Regions and Availability Zones. AWS maintains multiple geographic Regions, including Regions in North America, South America, Europe, China, Asia Pacific, South Africa, and the Middle East. Within these regions they maintain separate “Availability Zones” which are physically separated data centers within a region.
For philosophical reasons, we choose to keep all of our nodes within the Canadian Region, which is located in and around Montreal Quebec. This region has 3 separate availability zones, which are geographically distributed to ensure that unforseen events which take down a single data center (i.e. cut cables, flooding etc.) will not effect the other data centers.
To take advantage of this, the CANUK pool architecture has been modified as per the following diagram:
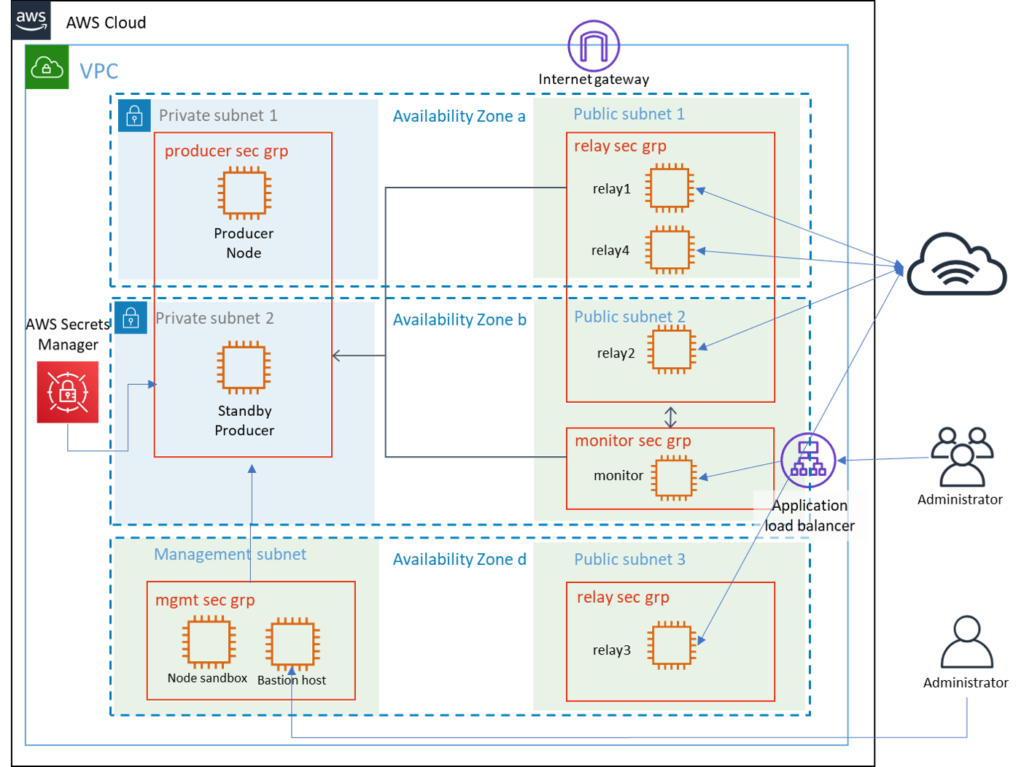
As you can see from the diagram above, our infrastructure is now spread among the three availability zones within the Canadian region. Should any of the availability zones go down from a network issue or datacenter problem, the remaining infrastructure will still stay up and available.
Availability Zone A contains two relays and our main producer node. If the other two availability zones should fail, our pool will still be operational with no intervention on our part.
Availability Zone B contains our backup producer, a single relay as well as our monitor node which collects metrics and serves up dashboards for our technical team. Should Zone A fail, the producer in this zone would be promoted to our primary producer node and uptime could be re-established within minutes of receiving an alert. Should zones A and D fail we would need to spin up a new management subnet within this zone in order to deploy our changes, however due to our automation processed this would be able to be accomplished quite rapidly.
Availability Zone D (yes… not C) contains a single relay, as well as our management server which provides secure connectivity to the rest of the nodes. If zones A and B were to both fail, we would be required to to spin up a new producer node and sync it with the network prior to coming back online, however with our infrastructure automation and frequent snapshots of our synced notes this is also achievable quite quickly.
That concludes are architecture updates. At the time of writing we are coming up quickly to the switch to epoch 211 which will be the first epoch which stake pool operators are creating blocks.
As always if you have any questions, always feel free to reach out to us via Telegram, Twitter or Email.